The aim of our recent activities within the topic of speech enhancement/separation was to develop new machine learning-based methods:
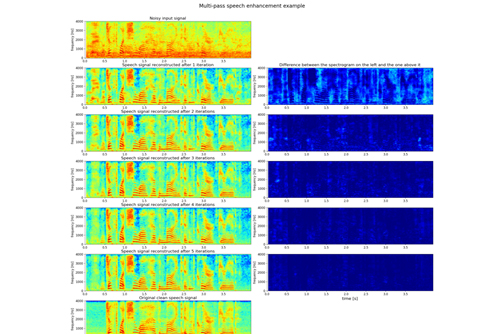
1.U-net with wide context units (WCUs) – which improved objective speech intelligibility/quality metrics in comparison to regular earlier U-nets with dilated convolutions .and method for training a speech enhancement neural network such that multiple propagations through results with better performance.
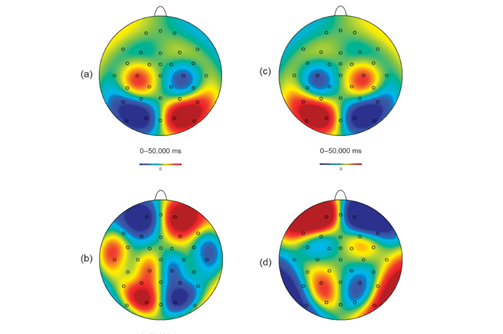
2.Using EEG signals to determine which of the sound sources a listener wants to listen to. We combined two techniques, which earlier were tested separately: neural tracking and alpha power lateralization.